


黃仁勳點名!SN三月暴漲五倍
原文作者:KarenZ,Foresight News
2026 年 3 月 20 日,All-In 創投播客中出現一場罕見對話。
知名風投人 Chamath Palihapitiya 向英偉達執行長黃仁勳介紹 Bittensor 生態中的一項突破——Templar 子網(SN3)成功以完全去中心化方式,在開放互聯網上完成大型語言模型的訓練,全程未依賴任何中心化數據中心。
黃仁勳並未迴避,而是將其類比為「Folding@home 的現代版本」:如同 2000 年代全球用戶貢獻閒置算力協同研究蛋白質摺疊,SN3 正在重現一種開放、協作、無需許可的 AI 計算範式。
僅在此前 4 天(3 月 16 日),Anthropic 聯合創始人 Jack Clark 於《Import AI》研究報告中專章詳述此成果:SN3 完成 720 億參數大模型 Covenant-72B 的分布式預訓練,性能表現與 Meta 於 2023 年發布的 LLaMA-2-70B 相當。他將該章節命名為「透過分布式訓練挑戰 AI 政治經濟學」,並明確指出:這不僅是技術驗證,更指向一個可能的未來——裝置端 AI 將廣泛採用去中心化訓練產出的開源模型,而雲端則持續運行專有大模型。
市場反應雖稍滯但極為強烈:SN3 代幣過去一個月漲幅逾 440%,兩週內飆升 340%,市值達 1.3 億美元;子網敘事爆發直接推升 Bittensor 原生代幣 TAO,一度衝至 377 美元,單月翻倍,完全稀釋估值(FDV)達約 75 億美元。
問題隨之而來:SN3 到底實現了什麼?為何引發跨圈層關注?去中心化 AI 的價值敘事,又將如何演進?
720 億參數,如何在開放網絡上誕生?
2026 年 3 月 10 日,Covenant AI 團隊於 arXiv 發布技術報告,正式宣告 Covenant-72B 完成訓練。這是一具 720 億參數的大型語言模型,由全球超過 70 個獨立節點(每輪約 20 個節點同步參與,每節點配備 8 張 NVIDIA B200 GPU)共同完成,訓練語料規模達約 1.1 兆 tokens。
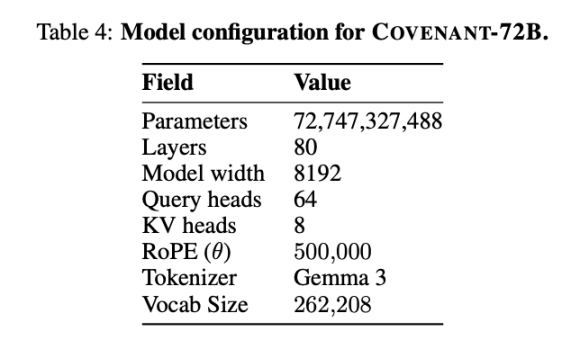
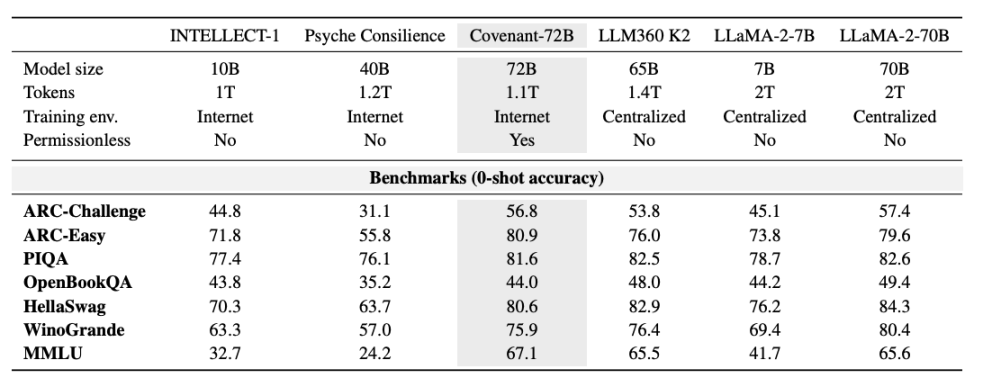
在基準測試方面,Templar 公布的 MMLU 得分為 67.1 分,對標 Meta 2023 年發布的 LLaMA-2-70B(65.6 分)。Jack Clark 明確提醒:若單看 2026 年前沿水準,Covenant-72B 已非最尖端——GPT、Claude、Gemini 等主流模型早已在數十萬張 GPU 上完成參數量破千億的訓練,其推理、程式碼與數學能力差距屬「數量級」而非「百分比」。
然而,若將前提限定為「純粹依靠開放互聯網上的異構、無許可、非中心化算力完成」,意義便截然不同。
對比其他去中心化訓練項目:INTELLECT-1(100 億參數)MMLU 僅 32.7;Psyche Consilience(400 億參數)僅 24.2。Covenant-72B 以 72B 規模與 67.1 分,成為目前去中心化訓練領域最具說服力的實證案例。
更關鍵的是,此次訓練採用無許可(permissionless)架構:任何人只要具備足夠算力,即可即時接入、成為參與節點,無需審核、無需白名單。全球各地的獨立節點真實協作,構成真正意義上的開放計算網絡。
黃仁勳的肯定,邊界在哪?
回顧播客現場,Chamath 描述 SN3 成就為「以分布式算力訓練 Llama 模型,全程保持狀態一致性」;黃仁勳回應時聚焦於「現代版 Folding@home」這一隱喻,並進一步闡述開源模型與專有模型長期共存的必要性。
須特別釐清的是:黃仁勳全程未提及 Bittensor 代幣、未評論投資價值、亦未延伸討論去中心化 AI 的商業或治理架構。他的背書,本質是對一種開放協作技術路徑的認可,而非對特定代幣或生態的站台。
Bittensor 子網機制:AI 的去中心化生產流水線
Bittensor 可視作一條專注於 AI 的公鏈平台,而其「子網(subnet)」則是各自獨立、目標明確的 AI 生產單元。每個子網定義自身任務、設計激勵模型,並透過 Bittensor 共識層協調資源與分配獎勵。
運作流程高度透明且去中心化: • 子網所有者設定目標並部署激勵規則; • 礦工提供算力,執行推理、訓練或儲存等任務; • 驗證者依據模型誤差改善幅度等指標,對礦工貢獻進行鏈上評分; • 最終由 Bittensor 的 Yuma 共識算法,根據累積得分自動分配 TAO 獎勵。
截至 2026 年 3 月,Bittensor 網絡已啟動 128 個子網,涵蓋推理服務、無伺服器 AI 雲、圖像生成、資料標註、強化學習、分散式儲存與通用計算等多元場景。
SN3 是其中極具戰略意義的一個:它不依賴現成 API,不包裝應用介面,而是直擊 AI 產業鏈最核心、最封閉、成本最高的環節——大模型預訓練本身。其願景清晰:證明無需昂貴的中心化超級計算集群,僅憑協調全球異構算力,同樣可產出高品質基礎模型。核心價值在於「平權」——打破算力壟斷,讓個人開發者與中小機構也能參與大模型時代的基礎建設。
推動 SN3 的核心團隊為 Templar(隸屬 Covenant Labs)。該團隊同時運營另外兩個緊密協同的子網:Basilica(SN39,專注分散式計算服務)與 Grail(SN81,專注強化學習後訓練與模型評估)。三者垂直整合,完整覆蓋「預訓練 → 對齊優化 → 模型評估」全流程,初步構建起去中心化大模型研發生態系統。
具體機制上:礦工上傳本地計算產生的梯度更新;驗證者以實際損失下降幅度(LossScore)評估貢獻品質;結果直接決定獎勵權重,全程無需信任第三方。
激勵設計的精妙之處在於:獎勵與「你的貢獻讓模型變好多少」直接掛鉤,而非單純計時或計算量。這從根本上抑制「摸魚」行為,解決去中心化環境中最棘手的信任難題。
技術突破:SparseLoCo 與 Gauntlet 如何破局?
讓數十個互不信任、硬體迥異、網路品質不一的節點協同訓練同一模型,面臨兩大根本挑戰: • 通信效率:傳統分布式訓練要求節點間高頻寬、低延遲互連; • 激勵相容:如何防止惡意節點提交錯誤梯度?如何確保各節點真正在訓練,而非複製他人結果?
SN3 採用兩大原創組件應對:
SparseLoCo —— 解決通信瓶頸 取代每步同步完整梯度的傳統做法,SparseLoCo 讓節點先在本地執行 30 步 AdamW 優化,再將產生的「偽梯度」壓縮上傳。壓縮策略包含 Top-k 稀疏化(僅保留關鍵梯度分量)、誤差反饋累積(保留被捨棄部分以補償下輪)、以及 2-bit 量化。最終壓縮比達146 倍以上。
換言之,原本需傳輸 100MB 的資料,現僅需不到 1MB。這使得系統在普通家庭寬頻(上行 110Mbps,下行 500Mbps)條件下,仍維持約 94.5% 的計算利用率——20 個節點、每節點 8 張 B200、每輪通信耗時僅 70 秒。
Gauntlet —— 解決激勵可信問題 作為部署於 Bittensor Subnet 3 上的智能合約,Gauntlet 對每位節點提交的偽梯度進行即時驗證:以小批量測試資料計算「採用該梯度後模型損失降低幅度」,得出 LossScore;同時交叉檢驗節點是否使用其被分配的專屬資料集訓練——若其在隨機資料上的損失改善反而優於指定資料,將被給予負分。
每輪僅選取 LossScore 最高的節點梯度參與聚合,其餘淘汰;超出名額者即時補位,保障系統韌性。整體訓練中,平均每輪納入 16.9 個節點梯度,累計參與的唯一節點 ID 超過 70 個。
去中心化 AI 的敘事轉向:從理想主義到務實驗證
Covenant-72B 的真實意義,不在於取代 GPT 或 Claude,而在於開啟四條關鍵路徑:
第一,打破「分布式訓練只適用於小模型」的技術偏見。儘管與頂尖模型仍有距離,但它驗證了可擴展性——規模提升不再是理論障礙。
第二,無許可參與已被證實可行。此前所有分布式訓練項目均採用白名單制;SN3 首次實現全開放接入,由驗證機制擔任「守門人」。這是邁向「真正去中心化」的實質一步。
第三,dTAO 機制促成子網價值的市場發現。透過允許子網發行自有 Alpha 代幣,並以 AMM 機制競爭 Bittensor 主網的 TAO 排放配額,SN3 等產出實績的子網得以建立粗糙但有效的價值捕獲通道。當然,此機制亦易受敘事與情緒驅動,模型品質難以被普通投資者獨立判斷。
第四,觸及 AI 權力結構的根本命題。Jack Clark 所稱「誰擁有 AI 的未來」,直指當前模型訓練被少數科技巨頭壟斷的現實。若分布式訓練持續取得技術突破,或可在特定領域(如垂直行業中小型前沿模型)催生真正去中心化的開發生態——儘管此前景仍屬遠期。
里程碑背後:一組不容忽視的關鍵問題
黃仁勳的類比極其精準:Folding@home 在分子模擬領域貢獻卓著,卻從未動搖藥廠的核心研發地位。SN3 同樣如此——它跑通了協議,驗證了方向,但距離重塑產業格局,尚有漫長距離。
值得深入探討的現實問題包括:
• MMLU 指標本身的局限性:公開基準題目與答案存在潛在洩露風險;且所對標的 LLaMA-2-70B 與 LLM360 K2 均為 2023–2024 年模型。若置於動態更新榜單或抗污染新基準(如 MMLU-Pro)下評估,結論可能更嚴謹。
• 數據壟斷仍是最大瓶頸:高品質對話、程式碼、數學推導與科學文獻,仍集中於巨頭、出版社與學術資料庫手中。算力可民主化,數據端卻維持寡頭結構——此矛盾至今未被充分討論。
• 安全性隱憂無法回避:無許可意味著你無法知悉 70 多個節點背後的主體與數據來源。Gauntlet 可篩除明顯異常梯度,但難以抵禦細微的數據投毒——例如某節點系統性在有害內容方向多訓練數輪,所產生的梯度變化足以通過 LossScore 篩查,卻可能造成模型行為的漸進式偏移。在金融、醫療、法律等高合規場景,使用數據來源不可追溯、訓練過程不可審計的模型,風險極高。
• 代幣價值邏輯的結構性依賴:Covenant-72B 本身以 Apache 2.0 開源授權發布,不綁定 SN3 代幣。持有 SN3 代幣,分享的是子網未來持續產出新模型所帶來的 TAO 排放收益,而非模型被使用的直接商業回報。此價值鏈高度依賴於持續的高品質訓練產出,以及 Bittensor 整體排放機制的長期健康運作。一旦訓練停滯或成果退步,代幣估值根基將動搖。
列出這些問題,絕非否定 Covenant-72B 的歷史性意義——它確實證明了一件曾被普遍認為「不可能」的事可以做到。但「做到了」與「意味著什麼」,是兩件截然不同的事。
SN3 代幣單月暴漲 440%,這段距離未必全是泡沫,更可能是敘事速度恆常快於現實進程。至於這段落差最終將被現實填補,抑或被市場理性修正,答案只有一個:取決於 Covenant AI 團隊接下來,真正交出什麼。
值得關注的信號包括:Grayscale 已於 2026 年 1 月正式提交 TAO ETF 申請,顯示機構資本正加速布局;另依規劃,Bittensor 將於 2025 年 12 月啟動每日 TAO 排放減半,供給端的結構性收緊仍在深化。
參考連結:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95
